情景介绍
MDC 是解决分布式服务日志追踪方案中的有效工具。比如现在有个分布式的项目 - alearner-api、alearner-service,该项目使用了阿里开源的框架dubbo,alearner-api作为consumer端,是和前端浏览器直接交互的模块,alearner-service作为provide端,是为consumer端提供一系列数据支持的模块。且consumer端和provide端均有多个实例部署在不同的主机上。基于以上情景,将会出现以下问题: 对于某一个固定的前端请求,在整个项目大流量访问的情况下,无法在后端的日志中精确的锁定该请求所涉及的日志,即无法快速准确的锁定该请求在consumer端和provide端的业务流程以及consumer端和provider端的对应逻辑。
下文较为专业的解释为:
映射的诊断上下文(简称MDC)是用于区分来自不同源的交叉日志输出的工具。当服务器几乎同时处理多个客户端时,日志输出通常是交错的。 MDC基于每个线程进行管理。子线程自动继承其父级的映射诊断上下文的副本。
该篇将在分析源码的基础上进行该种场景的解决,即:MDC在分布式服务多线程并发情况下的使用。
Mapped Diagnostic Context
以下是MDC类的注释,可以详细的说明该类的作用和应用场景。
* This class hides and serves as a substitute for the underlying logging
* system's MDC implementation.
*
* 该类隐藏并用作底层日志记录系统的MDC实现的替代。
*
* <p>
* If the underlying logging system offers MDC functionality, then SLF4J's MDC,
* i.e. this class, will delegate to the underlying system's MDC. Note that at
* this time, only two logging systems, namely log4j and logback, offer MDC
* functionality. For java.util.logging which does not support MDC,
* {@link BasicMDCAdapter} will be used. For other systems, i.e. slf4j-simple
* and slf4j-nop, {@link NOPMDCAdapter} will be used.
*
* 如果底层日志系统提供MDC功能,那么SLF4J的MDC,即这个类,将委托给底层系统的MDC。这次值得注意的
* 是,只有log4j和logback两个日志系统,提供MDC功能。对于不支持MDC的java.util.logging,将使用
* BasicMDCAdapter。对于其他系统,即slf4j-simple和slf4j-nop,NOPMDCAdapter
* 将被使用。
*
* <p>
* Thus, as a SLF4J user, you can take advantage of MDC in the presence of log4j,
* logback, or java.util.logging, but without forcing these systems as
* dependencies upon your users.
*
* 因此,作为SLF4J用户,您可以在存在log4j,logback或java.util.logging的情况下利用MDC,
* 但不必将这些系统强制为依赖于您的用户。
*
* <p>
* For more information on MDC please see the <a
* href="http://logback.qos.ch/manual/mdc.html">chapter on MDC</a> in the
* logback manual.
*
* <p>
* Please note that all methods in this class are static.
*
* 请注意,此类中的所有方法都是静态的。
再进一步,对于其底层的某些实现类对于MDC介绍:
A Mapped Diagnostic Context, or MDC in short, is an instrument for distinguishing interleaved log output from different sources. Log output is typically interleaved when a server handles multiple clients near-simultaneously. The MDC is managed on a per thread basis. A child thread automatically inherits a copy of the mapped diagnostic context of its parent.
翻译过来为:
映射的诊断上下文(简称MDC)是用于区分来自不同源的交叉日志输出的工具。当服务器几乎同时处理多个客户端时,日志输出通常是交错的。 MDC基于每个线程进行管理。子线程自动继承其父级的映射诊断上下文的副本。
MDC源码角度分析
该源码分析采用slf4j-api-1.8.0-beta2.jar版本,会与其他版本例如slf4j-api-1.7.25-sources.jar略有不同。
MDC Structure
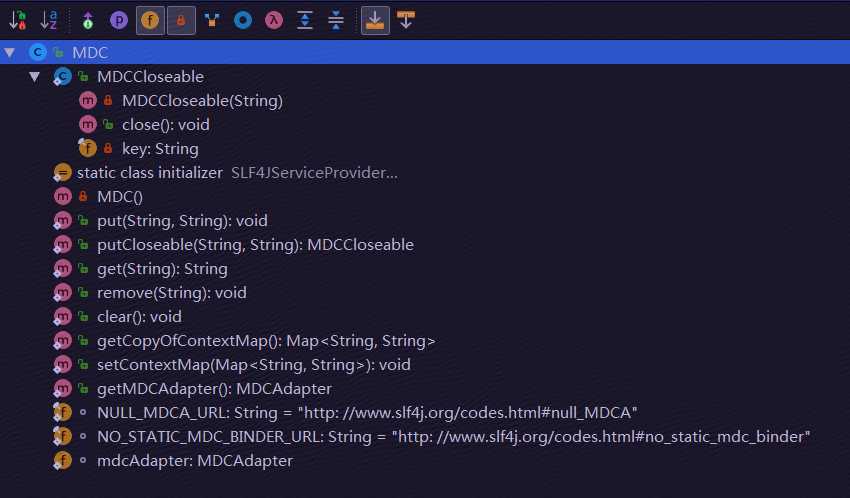
MDC Structure
MDC类结构中主要成员:
| # | 名称 | 返回值 | 作用 |
|---|---|---|---|
| 1 | MDC() | 无参构造 | |
| 2 | mdcAdapter | MDCAdapter | MDC适配器接口 |
| 3 | MDCCloseable | static class | 静态内部类 |
| 4 | put(String,String) | void | 向MDC中存放键值对 |
| 5 | putCloseable(String,String) | MDC.MDCCloseable | 创建一个特定key值的MDCCloseable对象,并将key、val存放入MDC,当对象调用close()方法时MDC删除该key对应的键值对 |
| 6 | get(String) | String | 获取某一特定key的值 |
| 7 | remove(String) | void | 移除某一特定key的键值对 |
| 8 | clear() | void | 清空所有储存的键值对 |
| 9 | getCopyOfContextMap() | Map<String, String> | 获取MDC中所有的键值对 |
| 10 | setContextMap(Map<String, String>) | void | 设置MDC的键值对 |
| 11 | getMDCAdapter() | MDCAdapter | 获得MDC的适配器 |
MDC的初始化
文章例子环境配置如下:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.8.0-beta2</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.3.0-alpha4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.3.0-alpha4</version>
</dependency>
初始化Code:
首先MDC类定义了一个成员变量mdcAdapter
static MDCAdapter mdcAdapter;
其次是在类的初始化过程中首先获得SLF4JServiceProvider接口的实现类(Provider实例对象),再者根据获得的Provider实例对象获得了MDCAdapter实例对象mdcAdapter
static {
SLF4JServiceProvider provider = LoggerFactory.getProvider();
if (provider != null) {
mdcAdapter = provider.getMDCAdapter();
} else {
Util.report("Failed to find provider.");
Util.report("Defaulting to no-operation MDCAdapter implementation.");
mdcAdapter = new NOPMDCAdapter();
}
}
对于初始化的代码块,第一步是获取SLF4JServiceProvider接口的实现类(Provider实例对象),在LoggerFactory源码中:
状态变量INITIALIZATION_STATE以及其他相关变量,修饰词volatile用于保证线程安全
static volatile int INITIALIZATION_STATE = 0; static final SubstituteServiceProvider SUBST_PROVIDER = new SubstituteServiceProvider(); static final NOPServiceProvider NOP_FALLBACK_FACTORY = new NOPServiceProvider(); static volatile SLF4JServiceProvider PROVIDER;
LoggerFactory.getProvider()源码如下,第一步主要是在异步情况下使用了performInitialization()获取对应的Provider并更新INITIALIZATION_STATE状态,第二步则是 根据初始化状态INITIALIZATION_STATE返回对应的Provider
static SLF4JServiceProvider getProvider() {
if (INITIALIZATION_STATE == 0) {
Class var0 = LoggerFactory.class;
synchronized(LoggerFactory.class) {
if (INITIALIZATION_STATE == 0) {
INITIALIZATION_STATE = 1;
performInitialization();
}
}
}
switch(INITIALIZATION_STATE) {
case 1:
return SUBST_PROVIDER;
case 2:
throw new IllegalStateException("org.slf4j.LoggerFactory in failed state. Original exception was thrown EARLIER. See also http://www.slf4j.org/codes.html#unsuccessfulInit");
case 3:
return PROVIDER;
case 4:
return NOP_FALLBACK_FACTORY;
default:
throw new IllegalStateException("Unreachable code");
}
}
对于performInitialization()代码,主要是Provider的绑定函数bind(),以及相关的版本校验versionSanityCheck()
private static final void performInitialization() {
bind();
if (INITIALIZATION_STATE == 3) {
versionSanityCheck();
}
}
bind()的核心在于findServiceProviders()-Provider发现函数,之后是根据发现函数获取的provider列表进行重复绑定的报告和当前使用的provider的报告
private static final void bind() {
try {
List<SLF4JServiceProvider> providersList = findServiceProviders();
reportMultipleBindingAmbiguity(providersList);
if (providersList != null && !providersList.isEmpty()) {
PROVIDER = (SLF4JServiceProvider)providersList.get(0);
PROVIDER.initialize();
INITIALIZATION_STATE = 3;
reportActualBinding(providersList);
fixSubstituteLoggers();
replayEvents();
SUBST_PROVIDER.getSubstituteLoggerFactory().clear();
} else {
INITIALIZATION_STATE = 4;
Util.report("No SLF4J providers were found.");
Util.report("Defaulting to no-operation (NOP) logger implementation");
Util.report("See http://www.slf4j.org/codes.html#noProviders for further details.");
Set<URL> staticLoggerBinderPathSet = findPossibleStaticLoggerBinderPathSet();
reportIgnoredStaticLoggerBinders(staticLoggerBinderPathSet);
}
} catch (Exception var2) {
failedBinding(var2);
throw new IllegalStateException("Unexpected initialization failure", var2);
}
}
对于findServiceProviders()-Provider发现函数,源码如下,主要是通过ServiceLoader加载了SLF4JServiceProvider接口的实现类
private static List<SLF4JServiceProvider> findServiceProviders() {
ServiceLoader<SLF4JServiceProvider> serviceLoader = ServiceLoader.load(SLF4JServiceProvider.class);
List<SLF4JServiceProvider> providerList = new ArrayList();
Iterator i$ = serviceLoader.iterator();
while(i$.hasNext()) {
SLF4JServiceProvider provider = (SLF4JServiceProvider)i$.next();
providerList.add(provider);
}
return providerList;
}
在这里要重点说一下ServiceLoader类的load方法和iterator方法。说到该方法就要提到SPI机制,即Service Provider Interfaces。SPI简单提一下,感兴趣的同学可以自己查找资料。
Java.util.ServiceLoader.load() Method
英文介绍:
The java.util.ServiceLoader.load(Class<S> service) method creates a new service loader for the given service type, using the current thread's context class loader.
中文翻译:
java.util.ServiceLoader.load(Class<S> service) 方法使用当前线程的上下文类加载器创建一个新的服务加载器的给定服务类型。
大白话:
java.util.ServiceLoader这个类来从配置文件中加载子类或者接口的实现类。主要是从META-INF/services这个目录下的配置文件加载给定接口或者基类的实现,ServiceLoader会根据给定的类的full name来在META-INF/services下面找对应的文件,在这个文件中定义了所有这个类的子类或者接口的实现类,返回一个实例。
Java.util.ServiceLoader.iterator() Method
英文介绍:
The java.util.ServiceLoader.iterator() method lazily loads the available providers of this loader's service. The iterator returned by this method first yields all of the elements of the provider cache, in instantiation order. It then lazily loads and instantiates any remaining providers, adding each one to the cache in turn.
中文翻译:
java.util.ServiceLoader.iterator() 方法懒加载这个服务加载器可用的提供者。此方法返回的迭代器首先以实例化顺序生成提供程序缓存的所有元素。迭代器首先通过此方法以实例化顺序生成程序provider(提供者)缓存的所有元素。然后,它懒加载并实例化任何剩余的提供者,依次将每个添加到缓存中。
到此,我们已经成功的获取到了SLF4JServiceProvider接口实现类,接下来就是根据获取到的Provider接口实现类获取具体的MDCAdapter,在我的环境中,我获取的SLF4JServiceProvider接口实现类是LogbackServiceProvider,获取到的MDCAdapter实现类为LogbackMDCAdapter
public class LogbackServiceProvider implements SLF4JServiceProvider
public class LogbackMDCAdapter implements MDCAdapter
该版本的LogbackMDCAdapter类的结构图如下:
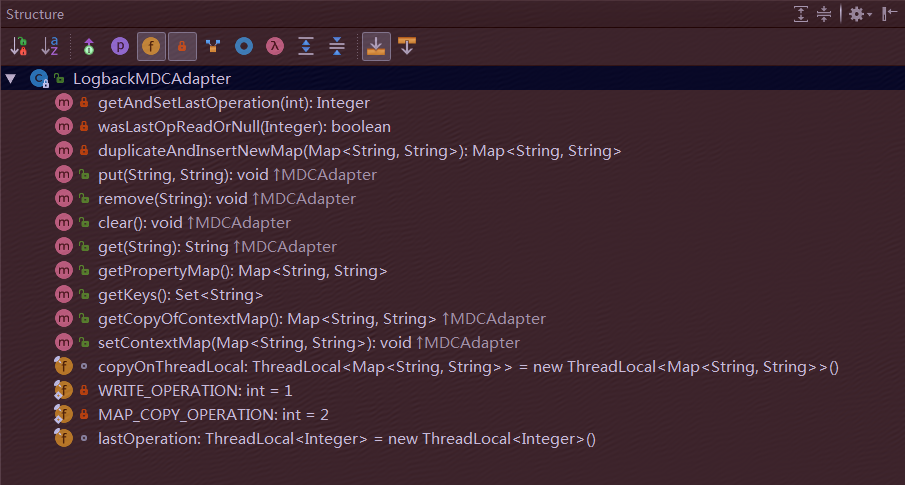
LogbackMDCAdapter Strcture
对于该新版本的改动,最重要的是移除了旧版本的CopyOnInheritThreadLocal,该类具体的说明如下:
The internal map is copied so as We wish to avoid unnecessarily copying of the map. To ensure efficient/timely copying, we have a variable keeping track of the last operation. A copy is necessary on 'put' or 'remove' but only if the last operation was a 'get'. Get operations never necessitate a copy nor successive 'put/remove' operations, only a get followed by a 'put/remove' requires copying the map.See http://jira.qos.ch/browse/LOGBACK-620 for the original discussion.We no longer use CopyOnInheritThreadLocal in order to solve LBCLASSIC-183 Initially the contents of the thread local in parent and child threads reference the same map. However, as soon as a thread invokes the put() method, the maps diverge as they should.
翻译为:
复制内部地图,以便避免不必要地复制地图。为了确保有效/及时复制,我们有一个变量跟踪上一次操作。'put'或'remove'需要复制,但前提是最后一次操作是'get'。获取操作永远不需要复制或连续的“put/remove”操作,只有get操作后跟“put/remove”操作需要复制地图。请参阅http://jira.qos.ch/browse/LOGBACK-620获取原始操作讨论。我们不再使用CopyOnInheritThreadLocal来解决LBCLASSIC-183(问题描述)问题。最初,父线程和子线程中本地线程的内容引用相同的映射。但是,一旦线程调用put方法,映射就会发生偏差。
LogbackMDCAdapter类中的主要成员及其作用:
| # | 名称 | 返回值 | 作用 |
|---|---|---|---|
| 1 | WRITE_OPERATION | int | value=1,写操作的状态码 |
| 2 | MAP_COPY_OPERATION | int | value=2,复制Map的状态码 |
| 3 | lastOperation | ThreadLocal | 跟踪上次执行的操作 |
| 4 | copyOnThreadLocal | ThreadLocal<Map<String, String>> | 复制当前线程的状态 |
| 5 | getAndSetLastOperation(int) | Integer | 获取并设置上次一操作状态 |
| 6 | wasLastOpReadOrNull(Integer) | boolean | 判断上一次操作是否为空或者是MAP_COPY_OPERATION状态 |
| 7 | duplicateAndInsertNewMap(Map<String, String>) | Map<String, String> | 复制并插入新的Map |
| 8 | put(String,String) | void | 将键值对放入当前线程的上下文Map中,不同于log4j,这里的值可以为null,如果当前线程没有上下文映射,则创建该调用作为该调用的附加操作。 |
| 9 | remove(String) | void | 删除 key 参数标识的上下文。 |
| 10 | clear() | void | 清除MDC中的所有条目。 |
| 11 | get(String) | String | 获取 key 参数标识的上下文。 |
| 12 | getPropertyMap() | Map<String, String> | 获取当前线程的MDC作为Map。此方法旨在在内部使用。 |
| 13 | getKeys() | Set<String> | 以Set的形式返回MDC中的键。返回的值可以为null。 |
| 14 | getCopyOfContextMap() | Map<String, String> | 返回当前线程的上下文映射的副本。返回值可能为null。 |
| 15 | setContextMap(Map<String, String>) | void | 首先清空MDC中存储的所有条目,其次将MDC中的条目更新为传入的Map |
进一步追溯LogbackMDCAdapter的实现,便会引出下一个核心要点,便是ThreadLocal,再进一步就是如何正确理解Thread、ThreadLocal、ThreadLocalMap这三者之间的关系。
下面 将采用笔者认为的一段对ThreadLocal比较中肯理解的部分。博客链接:Java进阶(七)正确理解Thread Local的原理与适用场景
ThreadLocal的理解
ThreadLoal 变量,它的基本原理是,同一个 ThreadLocal 所包含的对象(对ThreadLocal< String >而言即为 String 类型变量),在不同的 Thread 中有不同的副本(实际是不同的实例,后文会详细阐述)。这里有几点需要注意
- 因为每个 Thread 内有自己的实例副本,且该副本只能由当前 Thread 使用。这是也是 ThreadLocal 命名的由来
- 既然每个 Thread 有自己的实例副本,且其它 Thread 不可访问,那就不存在多线程间共享的问题
- 既无共享,就不存在同步问题,便不要和synchronize 作比较
那 ThreadLocal 到底解决了什么问题,又适用于什么样的场景?
This class provides thread-local variables. These variables differ from their normal counterparts in that each thread that accesses one (via its get or set method) has its own, independently initialized copy of the variable. ThreadLocal instances are typically private static fields in classes that wish to associate state with a thread (e.g., a user ID or Transaction ID).
Each thread holds an implicit reference to its copy of a thread-local variable as long as the thread is alive and the ThreadLocal instance is accessible; after a thread goes away, all of its copies of thread-local instances are subject to garbage collection (unless other references to these copies exist).
核心意思是
ThreadLocal 提供了线程本地的实例。它与普通变量的区别在于,每个使用该变量的线程都会初始化一个完全独立的实例副本。ThreadLocal 变量通常被private static修饰。当一个线程结束时,它所使用的所有 ThreadLocal 相对的实例副本都可被回收。
总的来说,ThreadLocal 适用于每个线程需要自己独立的实例且该实例需要在多个方法中被使用,也即变量在线程间隔离而在方法或类间共享的场景。后文会通过实例详细阐述该观点。另外,该场景下,并非必须使用 ThreadLocal ,其它方式完全可以实现同样的效果,只是 ThreadLocal 使得实现更简洁。
MDC的使用
作为区分来自不同源的交叉日志输出的工具。以某一请求唯一标识uuid为例,我们将从系统接受前端请求设置MDC、MDC在类似于RPC协议(Dubbo)上游的传输、MDC在RPC协议下游的接收、MDC在多线程边界的处理四个方面以及这三个方面中需要注意的问题作出介绍。
MDC的获取与设置
追踪某一特定请求的业务日志,自然是在请求之前就把uuid获取并且设置到,通常情况下,可以使用Filter或者Interceptor在请求之前完成对uuid的设置。
设置日志格式
在application.yml中增加如下配置:
logging:
pattern:
level: ' %X{uuid:-uuid} %X{user:-user} %5p'
参考网址 : Spring Boot Logging
有关MDC和logging.pattern.level部分截图如下:
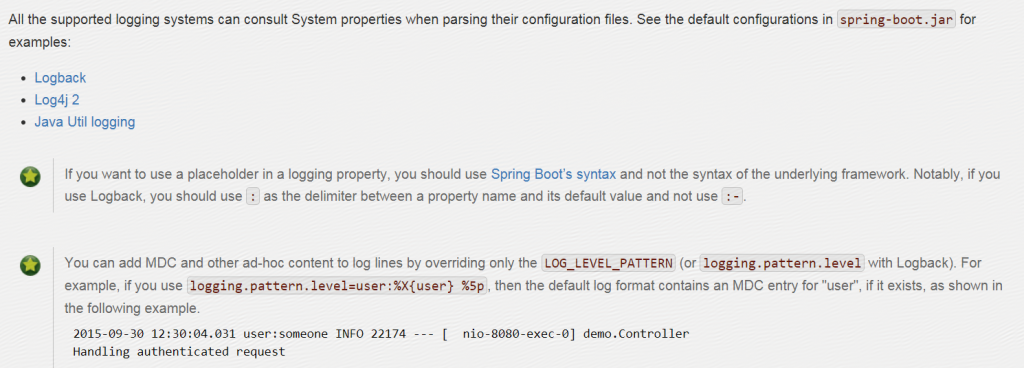
Spring Boot,MDC,logging.pattern.level
获取并设置
情景一:前端在request的header里添加uuid字段
使用Filter
获取uuid,为MDC设置uuid,请求结束后清空MDC均在doFilter方法中。特别注意,每次请求之后一定要清空MDC,即MDC.clear(),原因在后文提到。
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
LOGGER.info("Set MDC ");
HttpServletRequest httpServletRequest = (HttpServletRequest) servletRequest;
// 获取MDC
String uuid = httpServletRequest.getHeader(REQUEST_ID);
// 设置MDC
MDC.put(REQUEST_ID,uuid);
try{
filterChain.doFilter(servletRequest, servletResponse);
}finally {
// 一次请求之后,清空MDC
MDC.clear();
}
}
使用Interceptor
获取uuid和设置MDC都在preHandle方法里,清空MDC在postHandle方法里。Interceptor的preHandle、postHandle、afterCompletion的生效时间和顺序自行Google。
public class MdcInterceptor extends HandlerInterceptorAdapter {
private static final String REQUEST_ID = "uuid";
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 获取uuid
String uuid = request.getHeader(REQUEST_ID);
// 设置MDC
MDC.put(REQUEST_ID,uuid);
return true;
}
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable ModelAndView modelAndView) throws Exception {
// 请求结束后,清空MDC
MDC.clear();
}
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable Exception ex) throws Exception {
}
}
情景二:客户端程序为每个请求主动生成uuid,并将uuid添加到response的header里
情景一有一个缺陷,就是不通过前端访问某一接口,而是直接在浏览器中访问该接口,那么前端便不会传输uuid字段。该种场景便解决了这个问题。
首先,我们在后端生成uuid:
// 获取uuid String uuid= UUID.randomUUID().toString();
之后MDC设置完成uuid之后,将uuid字段放入response的header里
response.addHeader("uuid",uuid);
其他步骤同情景一类似,通过这样,我们便可以为任何途径进来的请求赋予一个uuid
MDC在多线程边界的处理
前文我们提到,MDC数据的存储是通过ThreadLocal实现的,ThreadLocal之和当前线程相关。也就是意味着,当我们使用多线程的时候,由主线程切换到其他线程时,MDC的数据是不能主动跨线程的。因为ThreadLocal是只存在于单个线程中,所以我们在使用多线程时,应该在主线程切换到其他线程的边界传输我们MDC的值并在新的线程内重新赋值。
下面我们借助一个例子来说明:
GitHub : MultithreadMdc.java
public class MultithreadMdc {
private static final Logger LOGGER = LoggerFactory.getLogger(MultithreadMdc.class);
private ExecutorService executorService = Executors.newCachedThreadPool();
public Map UpperCaseStrList(Map<String, String> map) {
LOGGER.info("UpperCaseStrList Method start");
LOGGER.info("map = {}", map);
Map<String, Future> res = new HashMap<>();
map.forEach((k, v) -> {
res.put(k, executorService.submit(new StringCallable(v)));
});
LOGGER.info("res = {}", res);
return res;
}
private class StringCallable implements Callable<Object> {
private final String str;
private final Map<String, String> mdcMap;
public StringCallable(String str) {
this.str = str;
mdcMap = MDC.getCopyOfContextMap();
}
@Override
public Object call() throws Exception {
LOGGER.info("call method start");
LOGGER.info("before setContextMap in this thread , Map of MDC is {}", MDC.getCopyOfContextMap());
LOGGER.info("***************************");
MDC.setContextMap(mdcMap);
LOGGER.info("after setContextMap in this thread , Map of MDC is {}", MDC.getCopyOfContextMap());
String res = str.toUpperCase();
LOGGER.info("str = {} , toUpperCase , res = {}", str, res);
LOGGER.info("after MDC clear in this thread , Map of MDC is {}", MDC.getCopyOfContextMap());
return res;
}
}
}
上述MultithreadMdc 类中,方法UpperCaseStrList中使用了多线程,其主线程与其他线程的边界为内部类StringCallable,笔者在多线程传输MDC的方法为:
- 自定义类的私有变量
private final Map<String, String> mdcMap;
- 在类的构造函数初始化mdcMap的值
public StringCallable(String str) { ······(其他初始化过程) mdcMap = MDC.getCopyOfContextMap(); } - 在新线程一开始便设置MDC在新线程的值
@Override public Object call() throws Exception { MDC.setContextMap(mdcMap); ······(其他业务逻辑) return res; } }
在第三步过程中,假如系统要进行相关RPC的调用,MDC在RPC协议间的传输在某种方法下(比如使用RpcContext传输)也需要在多线程的边界进行,因为RpcContext和MDC一样,同样是依赖于ThreadLocal实现的。具体传输方法请看下一小节(MDC在RPC协议上游的传输)的情景二。
MDC在RPC协议上游的传输
MDC中的数据在RPC协议上的传输,笔者认为可以从下面两个方法着手:
1、在数据传输的过程中,通过DTO(数据传输对象)将MDC的值传过去
例如一个DTO为RpcParam,其定义如下,我们可以将MDC.getCopyOfContextMap()的值 通过set方法放入HeaderParam的mdc变量里传输
public class RpcParam{
private HeaderParam headerParam;
private Map Body;
//There is Getter and Setter Code
}
public class HeaderParam{
private String id;
private String url;
private Map<String,String> mdc;
//There is Getter and Setter Code
}
2、以Dubbo为例,我们可以在系统的边界使用RpcContext来设置
RpcContext.getContext().setAttachment("uuid",uuid);
值得注意的是,假如rpc请求是在多线程中请求,即系统边界是在多线程里,那么我们仅仅使用上述的代码是足够的。但是,当我们的客户端程序是单线程的,一定要在一次请求之后或者下一次请求之前清空RpcContext,重新设置,防止数据污染,具体原因见后文。
清空RpcContext:
RpcContext.getContext().clearAttachments();
注意:当系统进行RPC调用的步骤是在多线程中时,对应的MDC放到RpcContext的传输需要放在多线程中。以上节的MultithreadMdc.java举例,对应的第三步传输的代码为
@Override
public Object call() throws Exception {
MDC.setContextMap(mdcMap);
······(其他业务逻辑)
RpcContext.getContext().setAttachment("uuid",MDC.get("uuid"));
return res;
}
}
MDC在RPC协议下游的接收
根据MDC在RPC协议上游的传输的两种方法,对应的MDC接收有以下两种:
1、下游获取到RpcParam后,使用get取得HeaderParam成员变量,进而在使用get方法获取HeaderParam的mdc变量,最后使用
MDC.setContextMap(mdc);
2、使用RpcContext来获取
RpcContext.getContext().getAttachment("uuid");
未完待续:
待添加内容:
总结~~~


文章评论