背景
该方案是在使用ClickHouse解决超高数据规模下以某种固定类型的研究对象为核心的场景下衍生出来的。该场景有两个要点(限制条件):
- 超大数据规模。单张表最大日均同步对应hive表中超千亿的数据量。
- 所有存储的数据都是以研究对象为核心或者是作为该研究对象的属性数据出现。在数据层面上,就是我们研究对象唯一标识(id)是作为所有数据主键或者联合主键的一部分。对应到业务的SQL查询逻辑上,尤其是大量的join查询,这些join查询都会将研究对象id作为关联条件查询。
举例来说: 在某个电商场景下,我们要研究消费者的相关数据,即以消费者为核心,那么与消费者相关的数据表如画像表,订单表,配送地址表,行为表等等,都是以消费者的唯一标识(user_pin)作为主键或者主键的一部分的。当数据量达到一定程度,使用ClickHouse视图表直接做join等关联查询已经达不到时效性要求时,可以参考该解决方案。
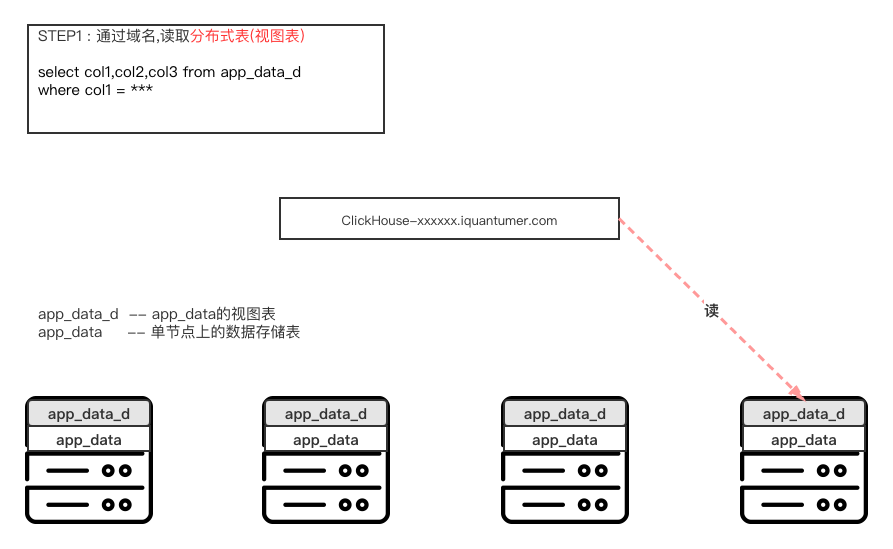
STEP2:SQL的分发执行
收到请求的节点,将sql分发到ck集群的每个shard上的某一节点上执行

STEP3:SQL的汇总、聚合与返回
收到请求的节点将所有数据汇总到该节点上,聚合后返回给客户端
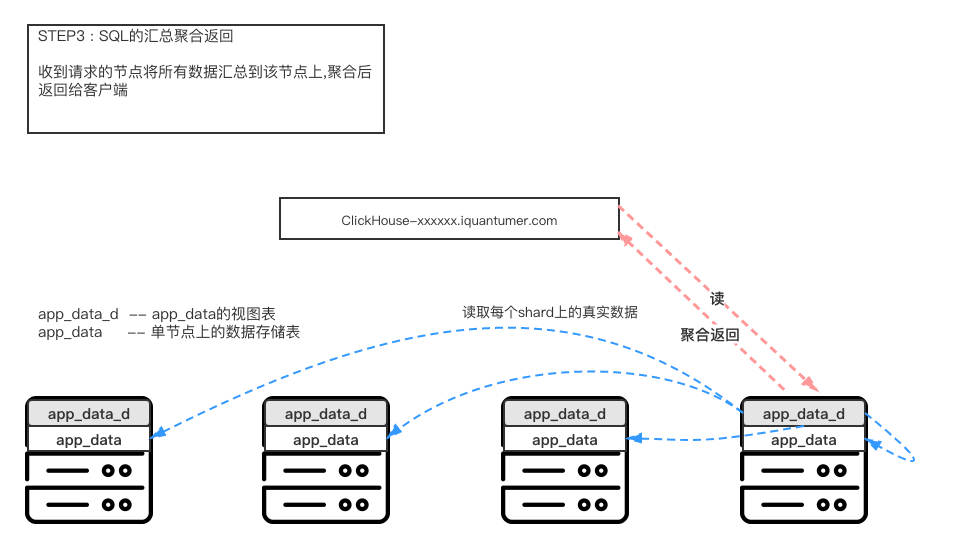
对于简单的视图表查询操作,底层执行流程大致按照上述步骤执行。但是遇见比较复杂的多张视图表的join操作时,执行流程将变得复杂起来。例如下面sql及其对应流程。
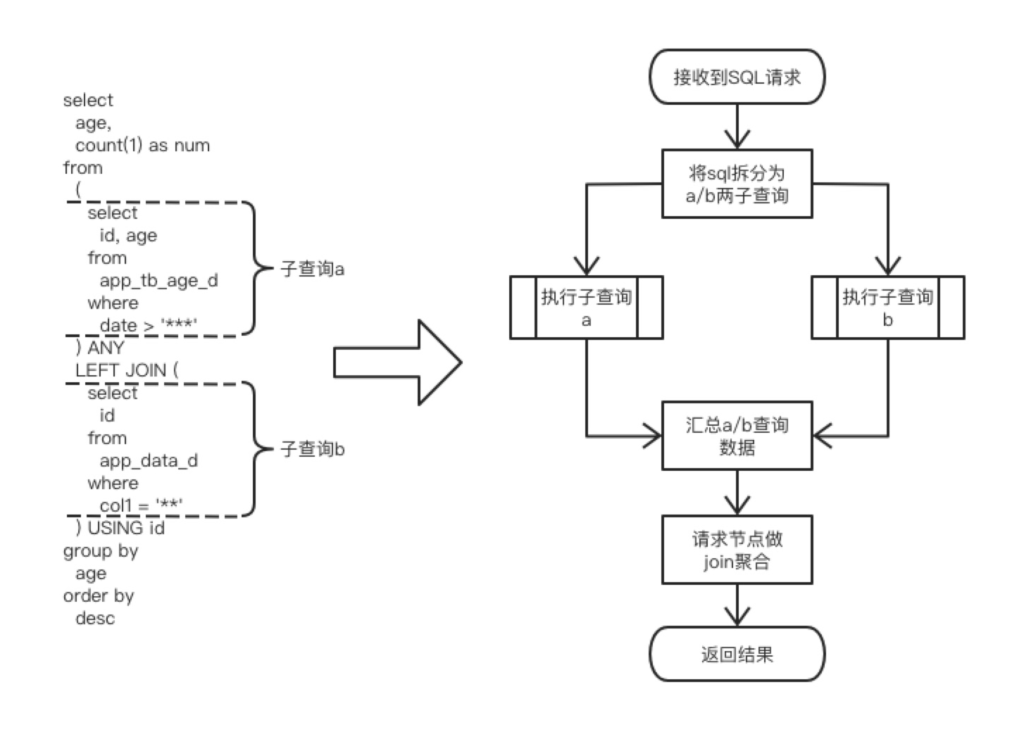
上述简单视图表的SQL查询和复杂的视图表SQL查询的流程可能和CK真正的执行流程有出入,但是大流程上是吻合的。
总的来说,当我们查询视图表时,对应CK集群实际上是做了一步类似MAP-REDUCE的操作,先将sql分发到所有的shard上去最后在某个节点上做聚合操作,尤其是join/group by等操作,会将每个待join的表的数据汇总到一个节点上再做具体的操作。由于单个节点的CPU/内存等资源是有限的,所以当需要处理的数据规模达到一定数量级时,单节点将不再能够有效的处理对应的数据。另外,在执行复杂的sql时,主要的耗时操作是大量的数据汇聚到某一节点后做子表层面的聚合这一步,最终导致执行sql的响应缓慢甚至超时。更严重的,当大量的类似请求全部打到同一个节点时,甚至有导致该节点宕机的风险。
但是CK的这种做法是可以理解的,因为CK的视图表查询逻辑势必是要具有通用性的,不具有通用性将会影响使用与推广。但是作为使用者的我们是可以在特殊场景下进行优化的。
定制化场景下的使用
文章在一开始便有个前提条件,便是超大数据规模,简单通过视图表做查询已经不能满足时效性要求。倘若数据规模不大,那么简单的使用视图表查询还是可以满足需求的。那么在超大数据规模这个前提下,所有存储的数据都是以研究对象为核心或者是作为该研究对象的属性数据出现,即研究对象的唯一标识(id)作为所有数据表的主键或者主键的一部分时,可以采用该解决方案。
方案原理简述
- 对于写数据:在往CK集群中写数据时,需要手动的保证同一个id对应的所有数据均存储在同一个shard上。
- 关于读操作:对于视图表不能支持的查询操作,尤其是将id作为join条件的查询操作,可以手动将sql分发到CK集群的每个shard上,之后通过程序汇总各个shard返回的结果,统一返回。
关于读操作
使用原理
根据上文我们已经知道读视图表的耗时操作是因为ck将所有的数据都汇总到一个节点上做聚合了。那么想要解决超时的问题,就要避免在某一固定的节点上做大量的聚合操作。 在该场景下,应对的解决原理大致如下:
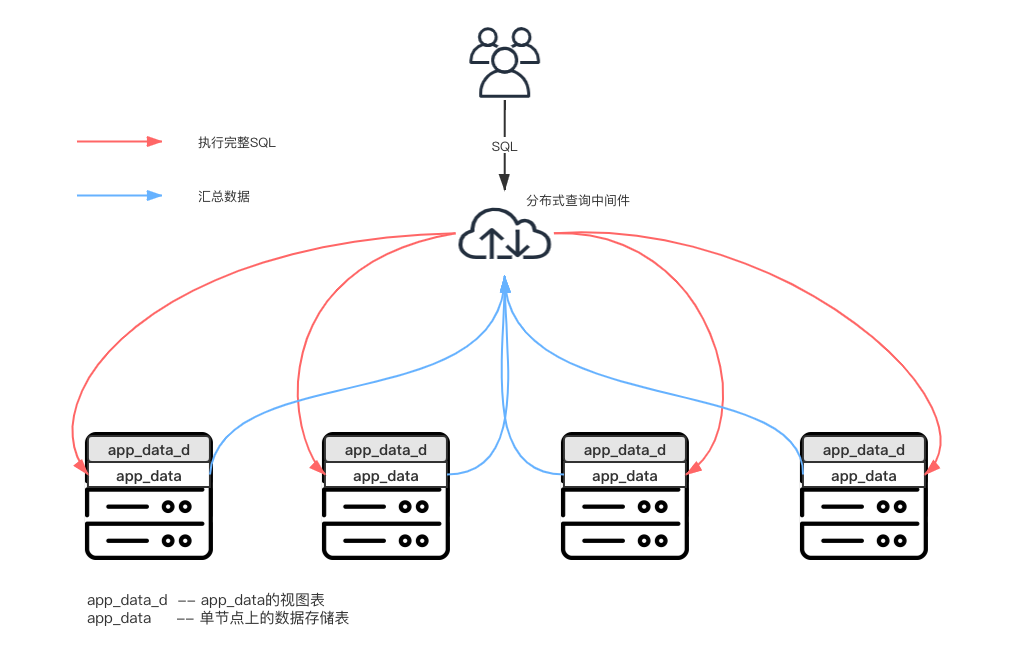
相应的对于复杂的查询操作,仍以上面join语句举例,对应的流程为:
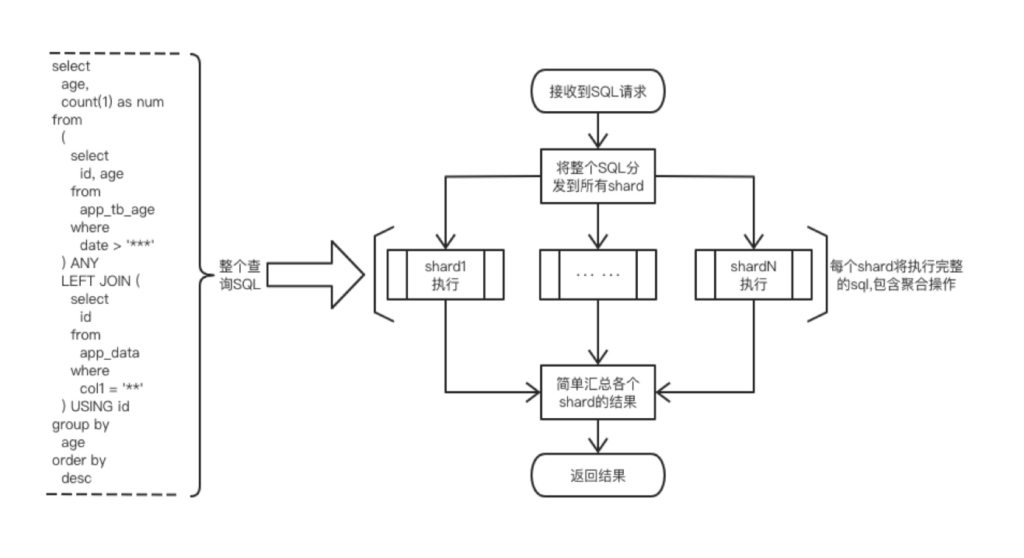
使用条件
想要使用上述方法,必须遵循下面几点:
- 所有的复杂查询均是围绕同一个分析对象,即研究对象的唯一标识(id)作为所有数据表的主键或者主键的一部分。
- 对于固定的研究对象id,该对象相关的所有数据均存储在CK集群的相同节点上。
- 在做复杂的JOIN操作时,研究对象id必须作为关联条件。
- 数据在CK集群上是均匀分布的,不能出现某个Shard上的数据占数据总量过高的情况。
上述三个条件是依次递进的,必须逐一满足。因为只有满足了上述三个条件,我们将SQL分发到CK集群的每个节点上执行获得的结果,根据select的维度做简单的数据加和,即是我们最终汇总之后的数据。但是,在这种场景下要避免下面这种情况:
- sql中禁止出现"乘/除/取余"等操作,因为该种sql执行之后无法汇总。
- 避免使用视图表进行查询,一旦使用视图表查询,对应节点将会去所有节点抓取真实数据,最终数据在绝大数情况下是不符合预期的。
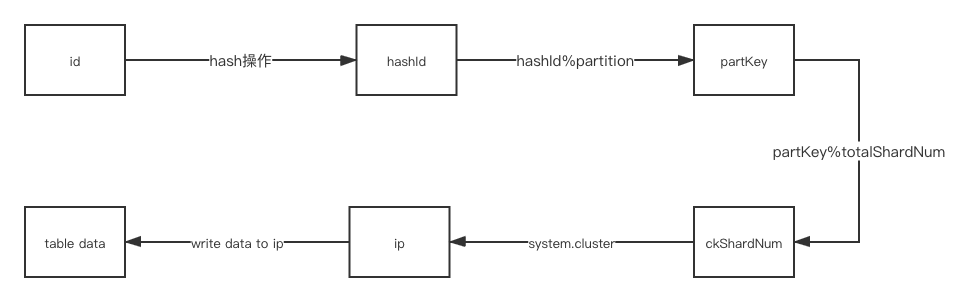
数据同步大致可以参考上图,流程大致如下:
- 对id做hash操作,将id同化生成hashId,避免后续步骤处理不了类似中文id的其他情况。
- 做hashId%partition的操作生成partKey,该步骤相当于spark中repartition操作,主要目的是为了均分所有的数据集,保证下一步可以将数据均匀的写入到ck集群的每个SHARD上去,这样可以保证sql在每个shard节点上执行的耗时基本一致。repartition的值建议尽量设置大一些,最好是ck集群shard数量的若干倍。
- partKey%totalShardNum得到ckShardNum。totalShardNum是CK集群中shard的数量,对于相同id的不同数据记录,其ckShardNum都是一样的。
- 将ckShardNum与ck集群的shard做固定的映射,通过ckShardNum可以得到确定的一组ip,该组ip均为固定shard上分片的ip
- 将ckShardNum相同的数据批量插入进对应的shard
如何校验写入数据的准确性
查看CK集群中每个shard中数据表的partKey,所有的partKey%totalShardNum均应一致。
不足
该情况下,扩展CK集群将需要重新同步数据
关于使用CK高级特性进行数据压缩
目前,数据增量日均千亿的hive表同步到ck后,将ck中记录条数压缩至hive中的1/3数量。
主要使用CK中arrayJoin函数特性。可以将hive中多行存储的同类数据,放入到一个Array中。 例如,hive中倘若有类似下面这种数据表。
|id |type |
|------|------|
|1 |a |
|1 |b |
|1 |c |
|2 |d |
|2 |e |
在CK中可以按照下面格式存储:
|id |typeArr |
|------|-----------|
|1 | [a,b,c] |
|2 | [d,e] |
arrayJoin类似行转列特性,行转列后还能做join/group by等操作。arrayJoin举例:
SELECT arrayJoin( [ 549042849318260 , 549042849330412 , 549042849318253 , 549042849318254 , 549042849318255 ] ) as dst;
|dst |
|--------------------|
|549042849318260 |
|549042849330412 |
|549042849318253 |
|549042849318254 |
|549042849318255 |
SELECT arrayJoin( [ 549042849318260 , 549042849330412 , 549042849318253 , 549042849318254 , 549042849318255,549042849318255 ] ) as dst,count(1) as num group by dst order by num desc;
|dst |num |
|-------------------|-------|
|549042849318255 |2 |
|549042849330412 |1 |
|549042849318254 |1 |
|549042849318260 |1 |
|549042849318253 |1 |其他高阶函数
目前经常使用的有:
- arrayJoin
- arrayMap
- arrayElement
CK中关于Array函数文档地址 : Functions for Working with Arrays


文章评论